https://galeri.uludagsozluk.com/r/2366253/+
Metinden görüntüye modeli, doğal dildeki bir girdi açıklamasını alan ve bu tanımlamayla eşleşen bir görüntü üreten bir makine öğrenimi modelidir.
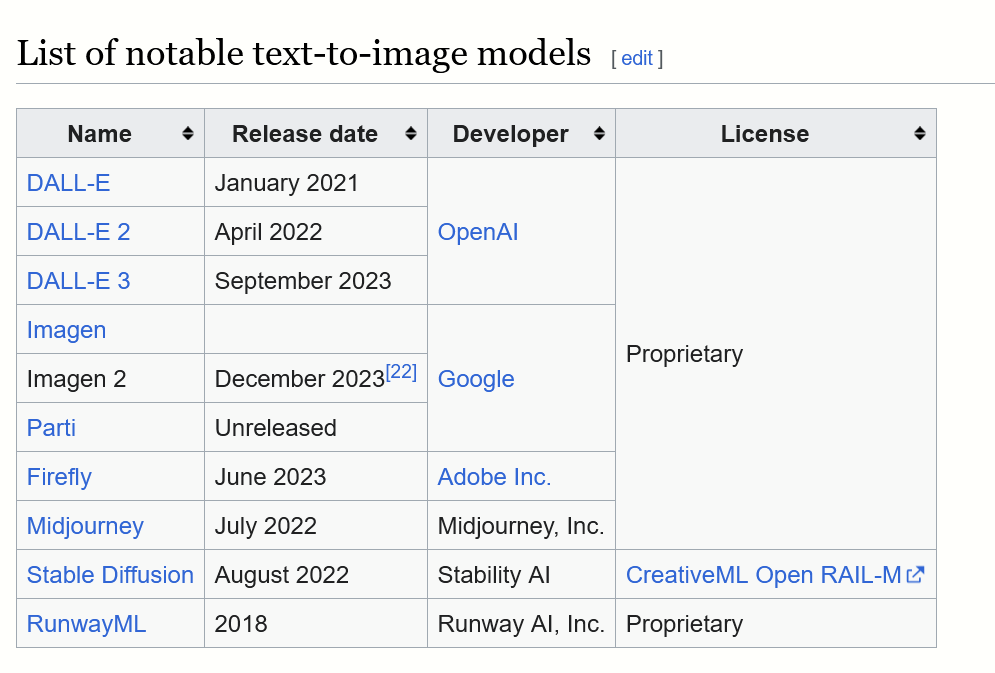
Metinden görüntüye modeller, derin sinir ağlarındaki ilerlemelerin bir sonucu olarak, 2010'ların ortasında yapay zeka patlamasının başlangıcında geliştirilmeye başlandı. 2022'de, OpenAI'nin DALL-E 2'si, Google Brain'in Imagen'i, Stability AI'nin Stable Diffusion'ı ve Midjourney gibi son teknoloji ürünü metinden resme modellerinin çıktılarının gerçek kaliteye yaklaştığı düşünülmeye başlandı.
Metinden görüntüye modeller genellikle girdi metnini gizli bir temsile dönüştüren bir dil modeli ile bu temsile göre koşullandırılmış bir görüntü üreten üretken bir görüntü modelini birleştirir. En etkili modeller genellikle web'den alınan büyük miktardaki resim ve metin verileriyle eğitilmiştir.
Derin öğrenmenin ortaya çıkmasından önce, metinden görüntüye modeller oluşturma girişimleri, küçük resim veritabanı gibi mevcut bileşen görüntülerinin düzenlenmesiyle yapılan kolajlarla sınırlıydı.
ilk modern metinden resme modeli olan alignDRAW, 2015 yılında Toronto Üniversitesi'nden araştırmacılar tarafından tanıtıldı. alignDRAW, daha önce tanıtılan DRAW mimarisini (dikkat mekanizmasına sahip tekrarlayan değişken bir otomatik kodlayıcı kullanan) metin dizilerine göre koşullandıracak şekilde genişletti.[4] alignDRAW tarafından oluşturulan görüntüler küçük çözünürlükteydi (yeniden boyutlandırmayla elde edilen 32x32 piksel) ve "çeşitlilik açısından düşük" olarak değerlendirildi. Model, eğitim verilerinde temsil edilmeyen nesnelere (kırmızı bir okul otobüsü gibi) genelleme yapabildi ve "mavi gökyüzünde bir dur işareti uçuyor" gibi yeni istemleri uygun şekilde ele aldı ve yalnızca "ezberleme" olmadığını gösteren çıktılar sergiledi. eğitim setinden elde edilen veriler
2016 yılında Reed, Akata, Yan ve ark. metinden resme görevi için üretken rakip ağları kullanan ilk kişi oldu.Dar, alana özgü veri kümeleri üzerinde eğitilen modeller sayesinde, "belirgin, kalın, yuvarlak gagalı, tamamen siyah bir kuş" gibi metin başlıklarından kuşların ve çiçeklerin "görsel olarak makul" görüntülerini oluşturmayı başardılar. Daha çeşitli COCO (Bağlamdaki Ortak Nesneler) veri seti üzerinde eğitilen bir model, "uzaktan... cesaret verici" ancak ayrıntılarında tutarlılıktan yoksun görüntüler üretti. Daha sonraki sistemler arasında VQGAN-CLIP, XMC-GAN ve GauGAN2 bulunur.
Kamuoyunun geniş ilgisini çeken ilk metinden görüntüye modellerden biri, Ocak 2021'de duyurulan bir transformatör sistemi olan OpenAI'nin DALL-E'siydi.
Daha karmaşık ve gerçekçi görüntüler oluşturabilen bir halef olan DALL-E 2, Nisan 2022'de tanıtıldı ve ardından Ağustos 2022'de halka açık Stable Diffusion geldi. Ağustos 2022'de, metinden resme kişiselleştirme, metinden resme temel modelinin eğitim setinde yer almayan yeni bir nesnenin küçük bir resim kümesini kullanarak modele yeni bir konseptin öğretilmesine olanak tanıyor. Bu, metnin tersine çevrilmesiyle, yani bu görüntülere karşılık gelen yeni bir metin teriminin bulunmasıyla gerçekleştirilir.
mimari ve eğitim süreci.
Metinden resme modeller çeşitli mimariler kullanılarak oluşturulmuştur. Metin kodlama adımı, uzun kısa süreli bellek (LSTM) ağı gibi tekrarlayan bir sinir ağıyla gerçekleştirilebilir, ancak transformatör modelleri o zamandan beri daha popüler bir seçenek haline gelmiştir. Görüntü oluşturma adımı için, koşullu üretken rakip ağlar (GAN'ler) yaygın olarak kullanılmakta olup, difüzyon modelleri de son yıllarda popüler bir seçenek haline gelmiştir. Metin yerleştirmeye dayalı yüksek çözünürlüklü bir görüntü çıktısı almak üzere bir modeli doğrudan eğitmek yerine, popüler bir teknik, bir modeli düşük çözünürlüklü görüntüler oluşturacak şekilde eğitmek ve onu yükseltmek için bir veya daha fazla yardımcı derin öğrenme modeli kullanmak ve daha iyi bir şekilde doldurmaktır.
veri kümeleri
Metinden görüntüye modelinin eğitilmesi, metin başlıklarıyla eşleştirilmiş bir görüntü veri kümesi gerektirir. Bu amaç için yaygın olarak kullanılan bir veri kümesi COCO veri kümesidir. Microsoft tarafından 2014 yılında piyasaya sürülen COCO, insan açıklamacılar tarafından oluşturulan, görüntü başına beş başlık içeren çeşitli nesneleri tasvir eden yaklaşık 123.000 görüntüden oluşuyor. Oxford-120 Çiçekler ve CUB-200 Kuşlar, her biri yaklaşık 10.000 görüntüden oluşan daha küçük veri kümeleridir ve sırasıyla çiçekler ve kuşlarla sınırlıdır. Konu aralığının dar olması nedeniyle bu veri kümeleriyle yüksek kaliteli bir metinden resme modelinin eğitilmesinin daha az zor olduğu düşünülmektedir.