görmek beni oldukça etkiledi. Lisa Su'nun AMD gemisini yönlendirmek için elinden geleni yaptığını GPU'larda daha iyi yapay zeka desteği Huggingface ortaklığı ve ikna edici bir şekilde George Hotz daha fazla hata raporu gönderecek.
(Bağlam için, Hotz, RX 7900 XTX desteğini iyileştirmek ve 15.000 $'lık bir cihaz satmak için 5 milyon $ topladı 65B parametreli LLM'leri çalıştıran önceden oluşturulmuş tüketici bilgisayarı. Çok sayıda sürücü neredeyse (Daha sonra çöküntüler yaşayınca AMD'den vazgeçiyordu .)
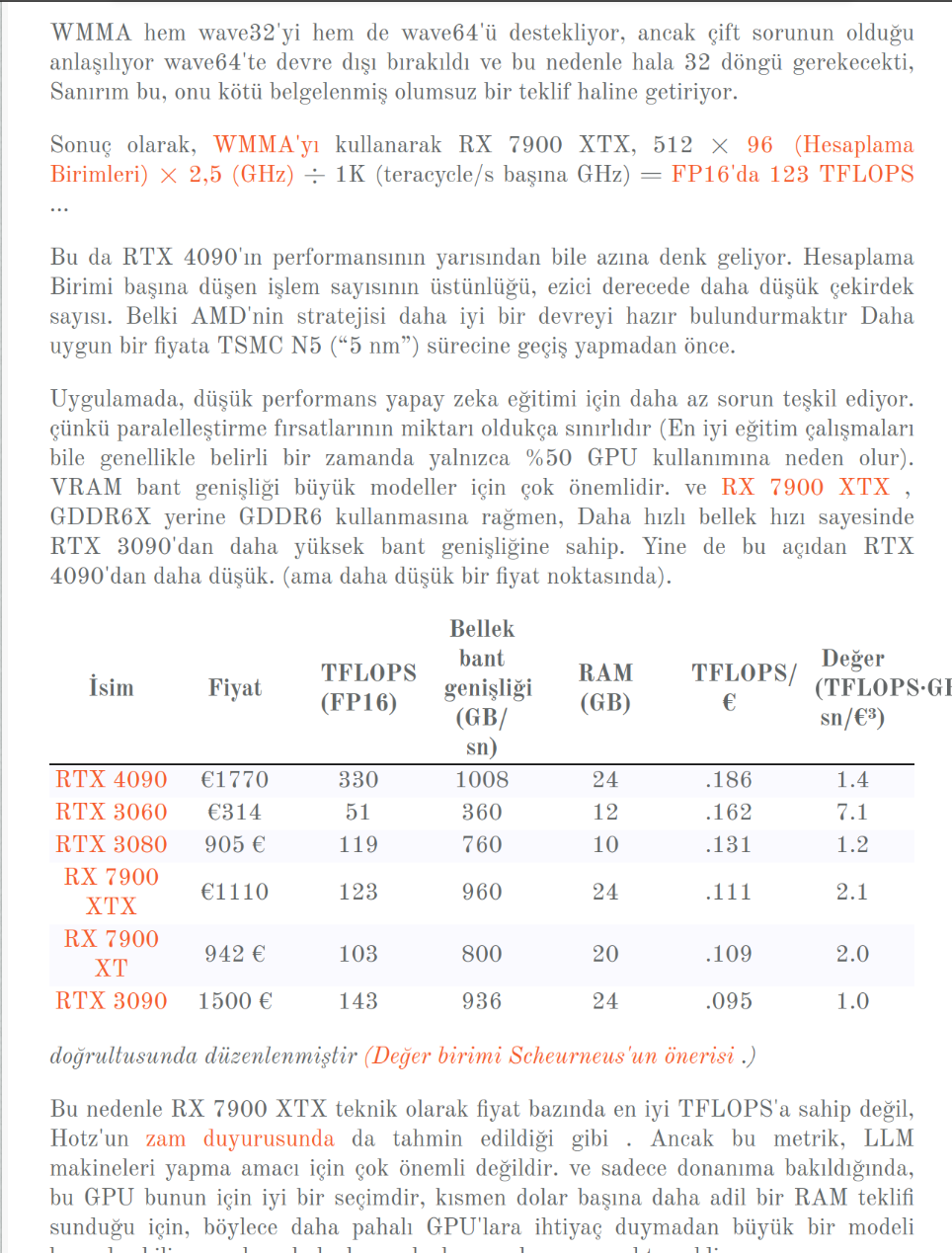
Ancak üstesinden gelinmesi gereken birkaç sorun var. Bu GPU harika olsa da ( GPU maliyeti başına Kararlı Difüzyon yineleme hızı en üst seviyededir), yüzeysel bir çalışma hatalı olacaktır: TechPowerUp, TomsHardware vb. gibi genel GPU kıyaslamaları şunları veriyor:
RX 7900 XTX: 123 TFLOPS
RTX 4090: 82,58 TFLOPS
Peki bu rakamlar nereden geliyor?
Resmi bir döküm olmasa da, sadece resmi rakamlar , insanlar bunu şu şekilde hesaplıyor:
için NVIDIA : Boost Saati (THz) × CUDA Çekirdekleri × 2 (FMA talimatı iki kayan nokta işlemi yaptığından (1 CUDA çekirdek döngüsünde bir çarpma ve bir toplama).
için AMD RDNA3'teki : Yükseltme Frekansı (THz) × Akış işlemcileri × 2 (çift sayı) × 4 (nokta ürünü) , gibi RDNA3'ün sahip olduğu V_DUAL_DOT2ACC_F32_F16, iki nokta çarpımı yapan (a×b+c×d+e, 4 işlem), 1 işlemci döngüsünde.
Ancak bu haksız bir karşılaştırmadır, çünkü AMD'nin talimatı daha dar bir alana yöneliktir. FMA'dan daha iyi (bu performans tatlı noktasına ulaşmak bu nedenle nadirdir), ve bu GPU'ların her ikisinin de kollarında başka numaralar olduğundan, üstün FLOPS'lar üretiyor.
en büyük sorun NVIDIA'daki Tensor çekirdekleridir . Onlarla, şu komutu çalıştırabilirsiniz: 4×4'ten 4×8'e matris çarpımı (sayfa 25) tek bir Tensör Çekirdek (32 CUDA çekirdeği) içinde 1 döngüde.